Why Bare Git Repository
For homework in 18-645(How to write fast code), I’m required to set up a bare git repository with command
$ git init --bare fastcode
Noticing the flag “–bare”, I wonder why we need this flag. After some searching, now it’s clear to me.
What a git repository contains
A normal git repository is a directory that contains
- Project directories and files (so called “working tree” or “working directory” ).
- A single directory called .git containing all of git’s administrative and control files.
As image below shows, we work on codes in working directory then “git add” changed files to staging area. Finally, we “git commit” to local repositoy.
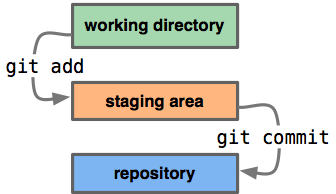
However, a bare repository does not contain working directory. It contains entire .git directory itself. Thus it’s not allowed to use “git add” or “git commit” in a bare repository directory. It’s created with “–bare” flag and conventionally named with suffix “.git”. For example, the bare version of git repository “repo” should be named “repo.git”.
When to use a bare repository
In short, when we want to share a repository.
A bare repository is mostly used as a central repository which receive push and accept being cloned or pulled. Why don’t we use a non-bare repository directly? Because pushing branches to a non-bare repository has the potential to overwrite changes.
A typical senario would be like this:
On machine A,
$ cd ~/repo/ $ git init $ git add a.file $ git commit -m a
Then on machine B,
$ git clone repo repo_b $ cd repo_b $ git add b.file $ git commit -m b $ git push
From code above, commit made on machine B is pushed to original repo on machine A. Now, if we “git status” on machine A, what will happen?
Actually, it would respond
# On branch master # Changes to be committed: # (use "git reset HEAD <file>..." to unstage) # # deleted: b.file
Why? Because git compares files in working directory with information from local .git directory, which is assumed to be always right. For here, on machine A, with newly pushed commit, .git directory says that there should be two files a.file and b.file. But in A working directory only a.file exists. Then git concluded that you deleted b.file.
Making similiar changes on machine B will always get ‘opposite’ results on machine A.
This kind of confusion can be avoided by using a bare repository. As bare repository doesn’t have a working directory, it doesn’t do comparision with working directory. It simplely records new commits and branch when you do push, or give you latest version of code when pull or clone.
Conclusion
Shared repositories should always be created with the “–bare” flag.
In fact, with latest version of git, the typical senario would not be repeatable. Because git sets configuration variable “receive.denyCurrentBranch” with “refuse” as default. Error message would be printed when you try to recur this example.
For repositories on GitHub server, I guess they should be bare. But their web interface has done lots of magic work to make it look like both bare and non-bare. Related discussion can be found on stackoverflow.
Reference
http://www.saintsjd.com/2011/01/what-is-a-bare-git-repository/
https://www.atlassian.com/git/tutorials/setting-up-a-repository/git-init/